
ROPO: Robust Preference Optimization for Large Language Models
Published in International Conference on Machine Learning (ICML), 2025
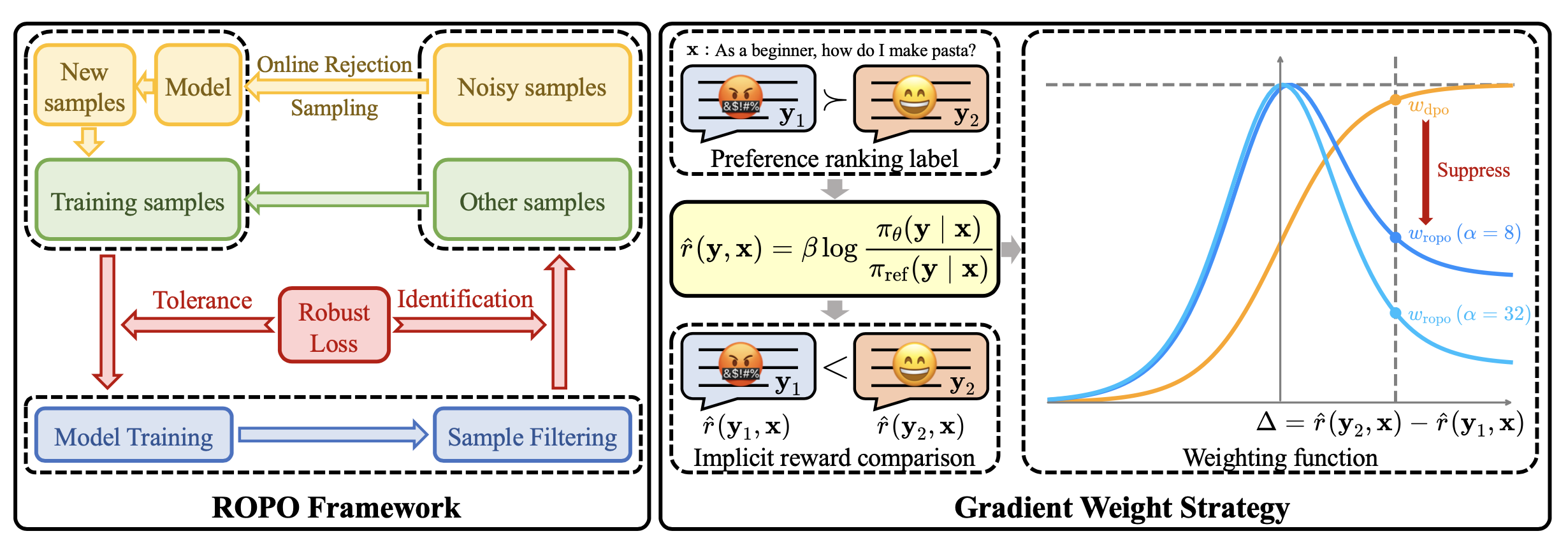
Preference alignment is pivotal for empowering large language models (LLMs) to generate helpful and harmless responses. However, the performance of preference alignment is highly sensitive to the prevalent noise in the preference data. Recent efforts for this problem either marginally alleviate the impact of noise without the ability to actually reduce its presence, or rely on costly teacher LLMs prone to reward misgeneralization. To address these challenges, we propose the RObust Preference Optimization (ROPO) framework, a novel iterative alignment approach that integrates noise-tolerance and filtering of noisy samples without the aid of external models. Specifically, ROPO first formulates the training process with adaptive noise reduction as an optimization problem, which can be efficiently solved in an iterative paradigm. Then, to enhance this iterative solving process with noise-tolerance and noise-identification capabilities, we derive a robust loss that suppresses the gradients from samples with high uncertainty. We demonstrate both empirically and theoretically that the derived loss is key to the noise-tolerance and effective filtering of noisy samples. Furthermore, inspired by our derived loss, we propose a robustness-guided rejection sampling technique to compensate for the potential important information in discarded queries. Experiments on three widely-used datasets of dialogue and post-summarization demonstrate that ROPO significantly outperforms existing preference alignment methods in the practical noise setting and under artificial random symmetric noise, with its advantage increasing as the noise rate increases.